
Cluster Sampling
Cluster sampling is a probability sampling method in which naturally occurring groups, known as clusters, are selected randomly from a population. Instead of selecting individual participants directly, researchers select entire clusters and then collect data from all members or a sample of members within those clusters.
On this page:
- Cluster Sampling Explained Simply
- What is Cluster Sampling?
- Cluster Sampling vs Stratified Sampling
- Types of Cluster Sampling
- Application of Cluster Sampling: an Example
- Advantages and Limitations of Cluster Sampling
- Common Mistakes When Using Cluster Sampling
- Cluster Sampling in Business Research
- Cluster Sampling in the Age of AI and Digital Research
- When to Use Cluster Sampling
- Dissertation Example
- Exam Tip
| Aspect | Cluster Sampling | Stratified Sampling |
|---|---|---|
| Population division | Into clusters | Into strata |
| Purpose | Improve practicality and reduce costs | Improve representation |
| Sampling unit | Entire cluster | Individual participants |
| Similarity within groups | Ideally diverse | Ideally similar |
| Cost | Lower | Higher |
| Sampling error | Usually higher | Usually lower |
| Common use | Large geographical populations | Diverse populations requiring subgroup representation |
Cluster vs stratified sampling (comparison table)
Cluster sampling selects groups, whereas stratified sampling selects individuals from each group.
Cluster Sampling Explained Simply
Imagine a researcher wants to study student satisfaction across all secondary schools in a city. Surveying every school would be expensive and time-consuming. Instead, the researcher randomly selects five schools and surveys students only within those schools. Each school acts as a cluster. This approach significantly reduces travel, costs, and administrative effort while still providing useful data.
Not sure whether cluster sampling or another probability sampling method is most suitable for your dissertation?
Get a clear, academically justified sampling strategy tailored to your research topic and objectives. Learn more about Dudovskiy AI Research Assistant.
What is Cluster Sampling?
Cluster sampling (sometimes referred to as one-stage cluster sampling) is a probability sampling technique in which the population is divided into naturally occurring groups called clusters. Researchers then select a number of clusters randomly and use those clusters as the source of data collection.
The primary objective of cluster sampling is to improve efficiency and reduce costs associated with data collection, especially when populations are geographically dispersed.
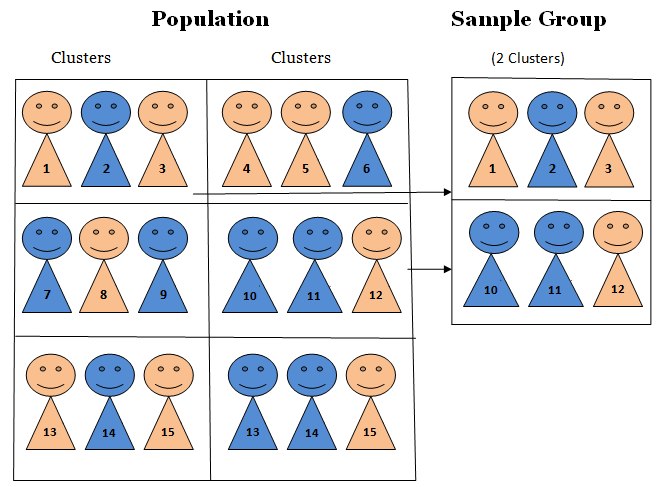
Unlike simple random sampling, where individual participants are selected directly, cluster sampling treats clusters themselves as sampling units. Examples of clusters may include schools, company branches, departments, cities, hospitals, retail outlets, or geographical regions.
Cluster sampling is particularly useful when creating a complete list of individual population members would be difficult, expensive, or impractical.
Cluster Sampling vs Stratified Sampling
Students frequently confuse cluster sampling with stratified sampling because both methods involve dividing populations into groups. The key difference lies in the purpose of the grouping.
In stratified sampling, researchers divide the population into strata and then randomly select individuals from every stratum. The goal is to improve representativeness. In cluster sampling, researchers randomly select entire clusters and collect data from those selected clusters only. The goal is to improve practicality and reduce costs.
Another important distinction is that strata should be internally similar but different from one another, whereas clusters should ideally resemble miniature versions of the entire population.
Types of Cluster Sampling
Cluster sampling can be implemented in two main forms.
In one-stage cluster sampling, all members of selected clusters are included in the study. For example, if five company branches are selected, every employee within those branches participates.
In two-stage cluster sampling, researchers first select clusters and then select individual participants within those clusters using another sampling technique. This second approach is particularly common in business research because it further reduces data collection costs while maintaining reasonable levels of representativeness.
Application of Cluster Sampling: an Example
Imagine you want to evaluate consumer spending on various modes of transportation in Greater London. Since Greater London is a large area, we need to sample from only 6 boroughs out of total 32 boroughs it comprises.
There are following five stages for the application of cluster sampling for this research:
1. Choosing target audience and sample size. The target audience for such a study is Greater London and sample size includes all the people living in Greater London.
2. Dividing population into clusters. Population in each cluster should be diverse and potential characteristics of the entire population should be represented in each cluster. Overlap between clusters should not exist, i.e. same people should not belong to more than one clusters. The Greater London consists of 32 boroughs. Each borough meets requirements above to be considered as a cluster. Accordingly, the area can be divided into 32 clusters with each cluster representing a borough.
3. Marking each cluster with a unique number. We can easily number each borough from 1 to 32.
4. Choosing a sample of clusters applying probability sampling. Usingsystematic random sampling (or any other probability sampling), we can choose 6 boroughs from the total 32 boroughs. It can be argued that these 6 boroughs can be considered as mini-representation of the entire Greater London. Households residing in 6 boroughs will represent samples for the study.
5. Choosing individual households to be included in the study. For this research we would be using multistage, rather than single stage cluster sampling. Accordingly, rather than using all households within selected 6 boroughs, we will choose certain households residing in these boroughs using probability sampling method such as systematic or stratified.


Download the manual and prepare to defend your methodology with confidence
John Dudovskiy
[1] Jackson, S.L. (2011) “Research Methods and Statistics: A Critical Approach” 4th edition, Cengage Learning